20 câu hỏi phỏng vấn Data Modeling (Mô hình hóa dữ liệu)

Để làm việc với dữ liệu, trở thành nhân sự của lĩnh vực phân tích dữ liệu, bạn cần phải chuẩn bị rất nhiều kiến thức và kỹ năng về data cho các vòng phỏng vấn. Các câu hỏi phỏng vấn data modeling mô hình hóa dữ liệu dưới đây sẽ giúp bạn chuẩn bị tốt hơn cho buổi phỏng vấn của mình.
Mô hình hóa dữ liệu là gì?
Một mô hình dữ liệu sắp đặt các yếu tố dữ liệu khác nhau và tiêu chuẩn hóa cách chúng liên quan đến nhau và các thuộc tính thực thể trong thế giới thực. Theo một cách logic, mô hình hóa dữ liệu là quá trình tạo ra các mô hình dữ liệu đó.
Các mô hình dữ liệu bao gồm các thực thể và các thực thể là các đối tượng và khái niệm mà dữ liệu chúng ta muốn theo dõi. Chúng được hiện hữu bằng các bảng trong cơ sở dữ liệu. Khách hàng, sản phẩm, nhà sản xuất và người bán là các thực thể tiềm năng.

Hiểu về quá trình mô hình hóa dữ liệu
Mỗi thực thể có các thuộc tính chi tiết mà người dùng muốn theo dõi. Chẳng hạn, tên của khách hàng được coi là một thuộc tính.
Với cách hiểu đó, hãy cùng xem qua các câu hỏi phỏng vấn data modeling dưới đây hoặc tham khảo khóa học data analyst cole với chương trình chuyên sâu về data model Power BI
Câu hỏi phỏng vấn Data modeling cơ bản
Loạt câu hỏi phỏng vấn mô hình hóa dữ liệu cơ bản dưới đây đều là những kiến thức cơ bản nhất bạn cần biết nếu muốn làm mô hình hóa dữ liệu:
Ba loại mô hình dữ liệu là gì?
- Mô hình dữ liệu vật lý – Đây là framework hoặc lược đồ mô tả cách dữ liệu được lưu trữ vật lý trong cơ sở dữ liệu.
- Mô hình dữ liệu khái niệm – Mô hình này tập trung vào cấp độ high level, quan điểm của người dùng về dữ liệu được đề cập.
- Các mô hình dữ liệu logic – Chúng nằm giữa mô hình dữ liệu vật lý và mô hình dữ liệu lý thuyết, cho phép sự logic của dữ liệu tồn tại ngoài việc lưu trữ vật lý.
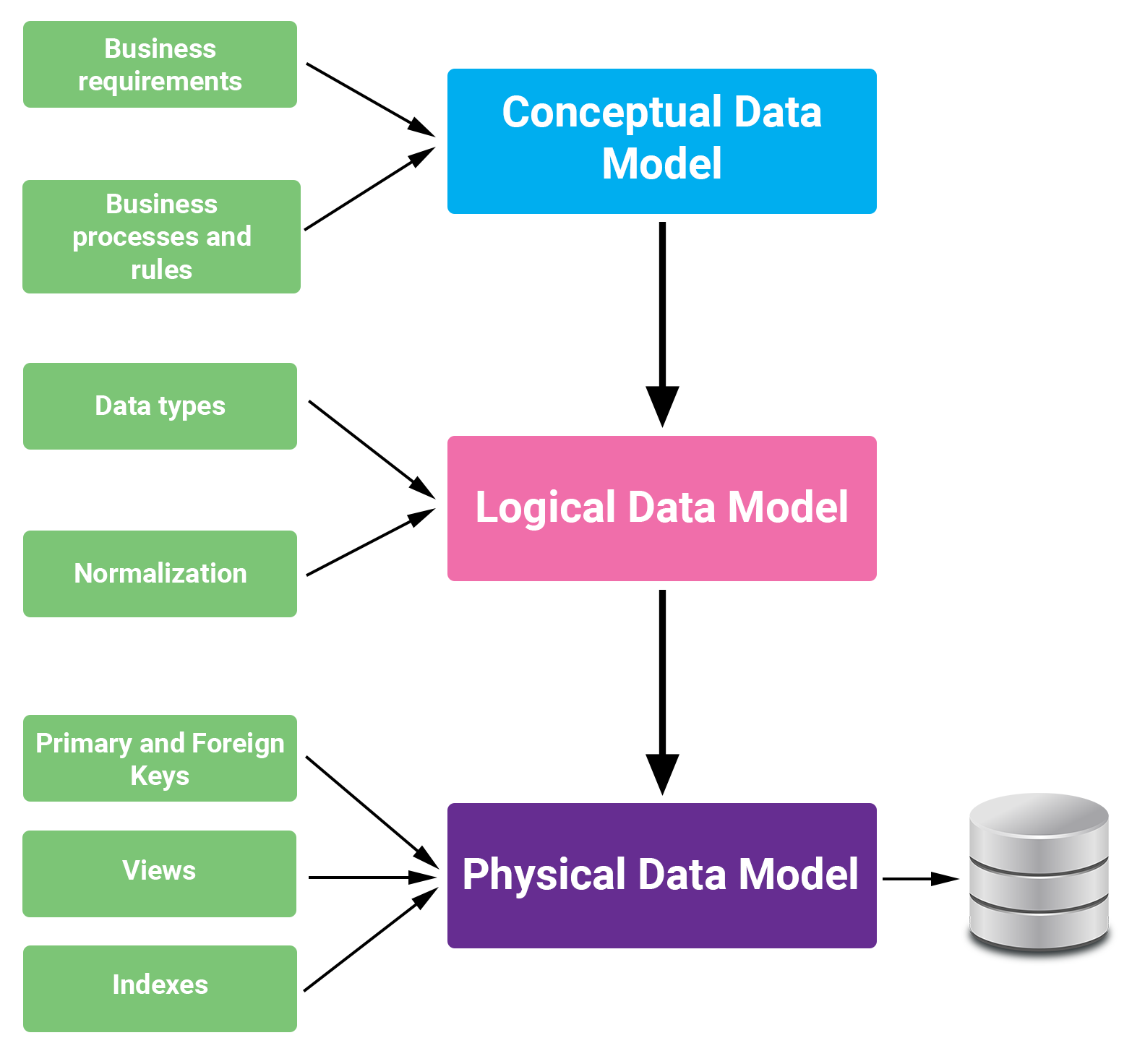
Các loại mô hình hóa dữ liệu
Table là gì?
Một table hay còn gọi là một bảng bao gồm dữ liệu được lưu trữ trong các hàng và cột. Các cột, còn được gọi là các trường, hiển thị dữ liệu theo sự liên kết dọc. Các hàng cũng được gọi là bản ghi hoặc tuple, đại diện cho sự liên kết ngang của dữ liệu.
Bình thường hóa là gì?
Bình thường hóa là quá trình thiết kế cơ sở dữ liệu theo cách giảm dư thừa dữ liệu mà không phải hy sinh tính toàn vẹn.
Mô hình hóa dữ liệu sử dụng bình thường hóa để làm gì?
Mục đích của bình thường hóa là:
- Xóa dữ liệu vô dụng hoặc dư thừa
- Giảm độ phức tạp dữ liệu
- Đảm bảo mối quan hệ giữa các bảng ngoài dữ liệu nằm trong các bảng
- Đảm bảo phụ thuộc dữ liệu và dữ liệu được lưu trữ một cách hợp lý
Vậy sự biến đổi là gì? Mục đích của sự biến đổi là gì?
Denormalization là một kỹ thuật trong đó dữ liệu dư thừa được thêm vào cơ sở dữ liệu đã được chuẩn hóa. Các thủ tục tăng cường hiệu suất đọc bằng cách hy sinh hiệu suất ghi.
ERD được viết tắt từ gì? Ý nghĩa của nó?
ERD là viết tắt của Entity Relationship Diagram – sơ đồ mối quan hệ thực thể – và là một đại diện thực thể logic, xác định mối quan hệ giữa các thực thể. Các thực thể cư trú trong các hộp và mũi tên tượng trưng cho các mối quan hệ.
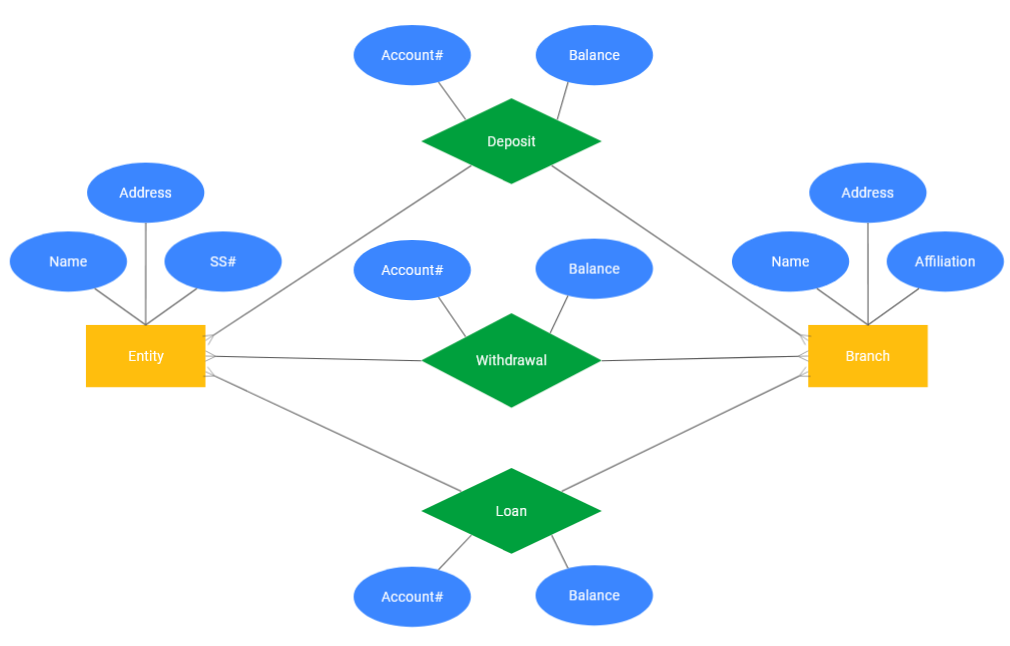
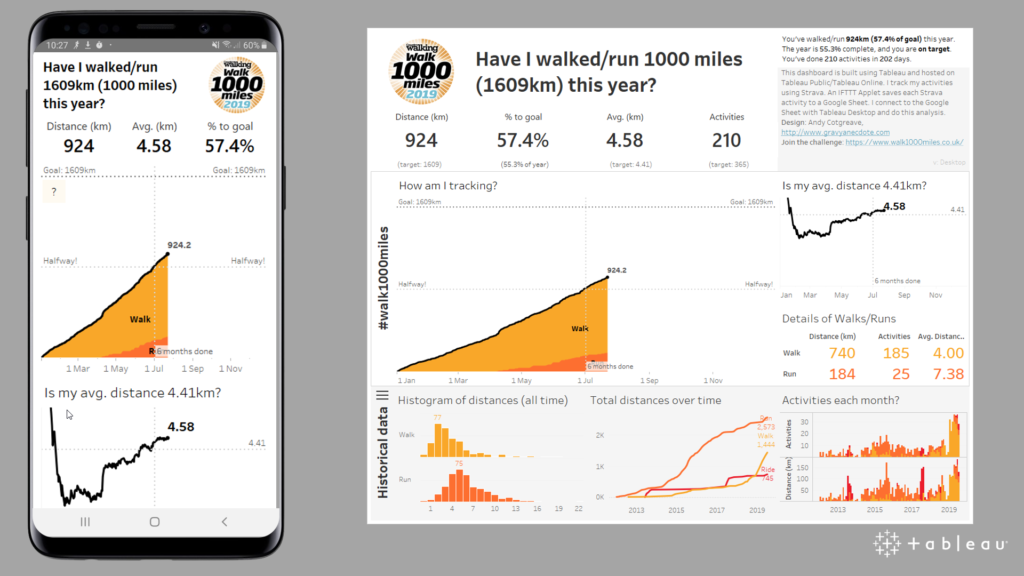
Sơ đồ Entity Relationship Diagram
Định nghĩa của khóa thay thế là gì?
Một khóa thay thế, còn được gọi là khóa chính, thực thi các thuộc tính số. Khóa thay thế này thay thế các khóa tự nhiên. Thay vì có các khóa chính hoặc tổng hợp, các chuyên viên mô hình dữ liệu tạo khóa thay thế, đây là một công cụ có giá trị để xác định hồ sơ, xây dựng các truy vấn SQL và tăng cường hiệu suất.
Các loại mối quan hệ quan trọng được tìm thấy trong mô hình dữ liệu là gì? Mô tả chúng.
Các loại mối quan hệ chính là:
- Xác định: một loại mối quan hệ thường kết nối các bảng cha mẹ và con cái. Nhưng nếu cột tham chiếu của bảng con là một phần của khóa chính của bảng, các bảng được kết nối bằng một đường dày, biểu thị mối quan hệ nhận dạng.
- Không xác định: nếu cột tham chiếu của bảng con không phải là một phần của khóa chính của bảng, các bảng được kết nối bằng một đường chấm chấm, biểu thị mối quan hệ không nhận dạng.
- Tự phục hồi: mối quan hệ đệ quy là một cột độc lập trong một bảng được kết nối với khóa chính trong cùng một bảng.
Mô hình dữ liệu doanh nghiệp là gì?
Đây là một mô hình dữ liệu bao gồm tất cả các mục yêu cầu của một doanh nghiệp.
Câu hỏi phỏng vấn mô hình hóa dữ liệu trung cấp
Các câu hỏi phỏng vấn data modeling trung cấp sẽ giúp người tuyển dụng có thể hiểu hơn về kỹ năng và kiến thức chuyên môn của bạn:
Những lỗi phổ biến nhất mà bạn có thể gặp phải trong mô hình hóa dữ liệu là gì?
Đây là những lỗi rất có thể gặp phải trong quá trình mô hình hóa dữ liệu mà bạn nên biết:
- Xây dựng các mô hình dữ liệu quá rộng: Nếu các bảng được chạy cao hơn 200, mô hình dữ liệu ngày càng trở nên phức tạp, làm tăng khả năng thất bại.
- Các key thay thế không cần thiết: Các phím thay thế chỉ phải sử dụng khi khóa tự nhiên không thể hoàn thành vai trò của khóa chính
- Mục đích bị thiếu: các tình huống có thể phát sinh khi người dùng không có manh mối về sứ mệnh hoặc mục tiêu của doanh nghiệp. Thật khó, nếu không phải là không thể tạo ra một mô hình kinh doanh cụ thể nếu người mô hình dữ liệu không có sự hiểu biết khả thi về mô hình kinh doanh của công ty.
- Khử biến không phù hợp: Người dùng không nên sử dụng chiến thuật này trừ khi có một lý do tuyệt vời để làm như vậy. Phục biến cải thiện hiệu suất đọc, nhưng nó tạo ra dữ liệu dư thừa, đây là một thách thức để duy trì.
Giải thích hai lược đồ thiết kế khác nhau
Hai lược đồ thiết kế được gọi là lược đồ sao và lược đồ tuyết. Lược đồ sao có một bảng thực tế tập trung với nhiều bảng chiều xung quanh nó. Lược đồ bông tuyết là tương tự, ngoại trừ mức độ bình thường hóa cao hơn, dẫn đến lược đồ trông giống như một bông tuyết.
Kích thước thay đổi chậm là gì?
Đây là các kích thước được sử dụng để quản lý cả dữ liệu quá khứ và dữ liệu hiện tại trong kho dữ liệu. Có bốn loại kích thước thay đổi chậm khác nhau lần lượt là: SCD loại 0 đến SCD Loại 3.
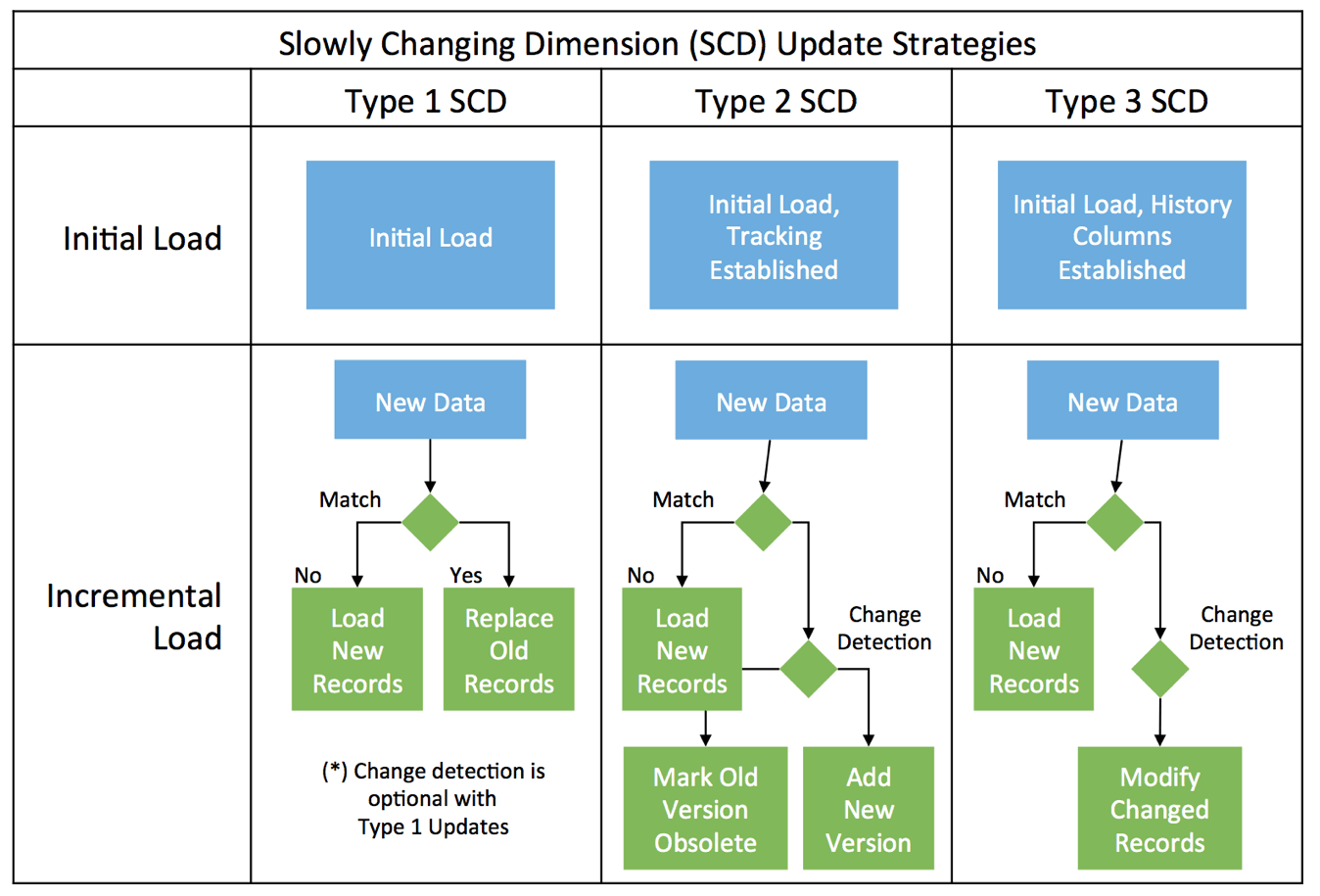
Chiến lược Slowly Changing Dimension
Data Mart là gì?
Data Mart là tập hợp kho dữ liệu đơn giản nhất và được sử dụng để tập trung vào một lĩnh vực chức năng của bất kỳ doanh nghiệp nào. Data Mart là một tập hợp các kho dữ liệu được định hướng theo một luồng kinh doanh hoặc khu vực có chức năng cụ thể của một tổ chức (ví dụ: tiếp thị, tài chính, bán hàng). Có thể nhập Data Mart bởi một loại hệ thống giao dịch, các kho dữ liệu khác hoặc thậm chí các nguồn bên ngoài.
Granularity – Độ chi tiết là gì?
Độ chi tiết đại diện cho mức độ thông tin được lưu trữ trong một bảng. Độ chi tiết được định nghĩa là cao hoặc thấp. Dữ liệu độ chi tiết cao chứa dữ liệu cấp giao dịch. Độ chi tiết thấp sẽ chỉ có thông tin cấp thấp, chẳng hạn như tìm thấy trong các bảng thực tế.
Data Sparsity – Độ thưa thớt dữ liệu là gì và nó tác động đến tổng cục như thế nào?
Mức độ dữ liệu thưa thớt xác định lượng dữ liệu chúng ta có cho kích thước hoặc thực thể được chỉ định của mô hình. Nếu không có đủ thông tin được lưu trữ trong kích thước, thì cần nhiều không gian hơn để lưu trữ các tập hợp này, dẫn đến cơ sở dữ liệu quá khổ, cồng kềnh.
Các thực thể phân nhóm và supertype là gì?
Các thực thể có thể được chia thành một số thực thể phụ hoặc được nhóm lại các tính năng cụ thể. Mỗi thực thể phụ có các thuộc tính có liên quan và được gọi là một thực thể phân nhóm. Các thuộc tính phổ biến cho mọi thực thể được đặt trong một thực thể cấp cao hơn hoặc siêu cấp, đó là lý do tại sao chúng được gọi là các thực thể SuperType.
Trong bối cảnh mô hình hóa dữ liệu, tầm quan trọng của Metadata – siêu dữ liệu là gì?
Siêu dữ liệu được định nghĩa là “dữ liệu về dữ liệu.” Trong bối cảnh mô hình hóa dữ liệu, đây ld dữ liệu bao gồm các loại dữ liệu trong hệ thống, những gì nó được sử dụng và ai sử dụng nó.
Metadata có quan trọng không?
Tất cả kiến thức trên thế giới sẽ vô dụng nếu bạn không biết áp dụng nó ở đâu. Nếu bạn biết những loại câu hỏi bạn sẽ được hỏi, bạn có thể xem lại tài liệu và sẵn sàng với những câu trả lời tốt nhất. Hy vọng các câu hỏi phỏng vấn mô hình hóa dữ liệu trên đây có thể giúp bạn có sự chuẩn bị tốt nhất cho buổi phỏng vấn của mình. Ngoài ra, bạn có thể tham khảo case study data modeling tạo ra ER Model để hiểu rõ về quá trình hoạt động và trả lời trơn tru hơn..
Bài liên quan



Bạn muốn nhận tư vấn miễn phí về các khóa học tại Cole.vn?
Đăng ký ngay để nhận các thông tin ưu đãi
